

In this digital age, businesses generate large amount of data on daily basis. This “big data” holds valuable information that can drive growth, improve decision making and make the product or service competitive. To utilize this information, companies rely on powerful big data analytics platforms which are designed to process, analyze and visualize data at large scale.
In this guide, we shall compare and suggest best big data analytics platforms for businesses, like Hadoop, Spark and Cloudera. We shall break down their key features, benefits and suitability for different business needs.
What to Look for in a Big Data Analytics Platform
When selecting a big data platform, it’s essential to consider:
1. Scalability: How well does the platform scale with increasing data?
2. Data Processing Speed: Can it handle real-time analytics and batch processing?
3. Ease of Integration: How seamlessly does it integrate with other software or data sources?
4. Security Features: Does it meet your data privacy and security needs?
5. Cost Efficiency: Is the pricing model suitable for your budget?
6. Support and Community: How robust is the support network, including documentation and user communities?
These factors influence how well a platform will serve a business, from startups to large enterprises.
Top Big Data Analytics Platforms for Businesses
1. Apache Hadoop
Overview
Apache Hadoop is one of the pioneering platforms in big data analytics. It’s an open source framework that enables distributed storage and processing of large datasets across clusters of computers. Hadoop is known for its scalability and capacity to handle massive data volumes.
Key Features:
– Hadoop Distributed File System (HDFS): Efficiently stores large files across multiple machines, which provides both scalability and fault tolerance.
– MapReduce: Hadoop uses the MapReduce programming model to process massive data sets in parallel, which enhances efficiency.
– YARN: Manages resources across the Hadoop cluster, which improves operational efficiency.
– Integration: Hadoop supports various data sources and integrates with other big data tools, such as Apache Hive for SQL queries and Apache Pig for scripting.
Benefits:
– Cost effective: Being open source, Hadoop can reduce costs significantly for businesses who want affordable storage solutions.
– Scalability: Hadoop is highly scalable, which makes it suitable for both mid sized businesses and large enterprises that handle petabytes of data. Companies can easily add more nodes to the system as their data needs grow, to ensure flexibility without a complete overhaul.
– Large open source community for support and continuous updates.
– Compatible with on premises and cloud deployments.
Best For:
Hadoop is ideal for organizations that need to store large volumes of unstructured data (e.g., log files, raw data etc.) and want a cost effective, scalable solution. It is a great choice for industries like finance, telecommunications and e-commerce, where data is constantly generated at high volumes.
Example: Yahoo was one of the first major adopters of Hadoop, using it to manage its massive data infrastructure for search results, user interactions and content recommendations.
2. Apache Spark
Overview
Apache Spark is an open source analytics engine focused on speed and ease of use for big data processing. Unlike Hadoop, which relies on disk based storage, Spark processes data in memory, which makes Spark significantly faster than traditional disk based processing.
Key Features:
– In memory Processing: Data is stored in RAM, which results in faster performance for iterative tasks and complex computations.
– Rich API Support: Provides APIs in multiple languages, including Java, Scala, Python and R, which makes it versatile for data science and machine learning tasks.
– Integrated Libraries: Spark includes MLlib for machine learning, Spark SQL for SQL based queries, and GraphX for graph processing.
Benefits
– Speed: Spark is known for its lightning fast data processing capabilities, especially useful for real time data analytics.
– Ease of Use: Supports multiple programming languages, which makes it accessible to data scientists and engineers.
– Scalability: Spark is highly scalable and suitable for both batch and stream processing. It can run on various environments, such as standalone, Hadoop and cloud based infrastructures, which makes it versatile for businesses of all sizes.
Best For:
Spark is ideal for companies needing real time data processing, particularly those in technology, banking, and logistics where data speed is very important. It’s also widely used in machine learning applications due to its strong library support.
3. Cloudera
Overview
Cloudera provides a comprehensive big data platform that integrates Hadoop and other open source projects into a user friendly environment with added enterprise features. Its Cloudera Data Platform (CDP) is designed to support hybrid cloud and multi cloud deployments, suitable for large scale enterprises. It combines the power of Hadoop and Spark with a range of tools, including data governance and security features.
Key Features:
– Unified Data Platform: Allows businesses to run on both private and public clouds with Cloudera Data Platform (CDP).
– Data Governance and Security: Cloudera offers robust data governance, security and compliance features, including data encryption and access controls.
– Data Lifecycle Management: Offers tools for managing data from ingestion to analysis and archiving.
– Machine Learning: Cloudera supports machine learning and advanced analytics through its integrated tools.
Benefits:
– Enterprise Grade Security: Advanced security options make it a popular choice for industries with strict compliance requirements.
– Flexibility: Supports hybrid and multi cloud deployments, which gives businesses flexibility to run applications wherever they are most efficient.
Best For:
Cloudera is best for large enterprises in sectors like finance, healthcare and government institutions that require stringent security, compliance and data governance. It is also ideal for large businesses operating in multi cloud environments.
4. Amazon EMR
Overview
Amazon Elastic MapReduce (EMR) is a cloud based big data platform offered by Amazon Web Services (AWS). EMR makes it easy to process large amounts of data using Hadoop, Spark and other frameworks.

Key Features:
– Scalability and Flexibility: Allows you to scale compute resources up or down, depending on workload demands.
– Integration with AWS: Seamlessly integrates with other AWS services, like S3 for storage, which allows for an efficient data ecosystem.
– Automated Cluster Management: Handles cluster provisioning, configuration and tuning, which minimizes administrative overhead.
Benefits:
– Cost Control: Flexible pricing models, including on demand and spot instances, which allows businesses to control costs.
– High Availability: Built on AWS’s highly available infrastructure, which ensures minimal downtime.
Best For
Amazon EMR is ideal for businesses already using AWS, such as e-commerce platforms or media companies who need large scale data processing and storage capabilities.
5. Microsoft Azure HDInsight
Overview
Azure HDInsight is Microsoft’s big data solution based on Apache Hadoop. It’s a fully managed cloud service that supports a range of analytics tools, which includes Hadoop, Spark and Kafka.
Key Features:
– Broad Compatibility: Supports multiple languages and frameworks, such as R, Python and Java.
– Integration with Azure Ecosystem: Works seamlessly with Azure Active Directory, SQL Data Warehouse and Power BI.
– Security Features: Offers encryption, Active Directory integration and firewall options for enhanced security.
Benefits:
– Seamless Integration: Easily integrates with other Azure services, which makes it easier to manage data across different applications.
– Cost Efficiency: Pay-as-you-go model, ideal for companies who need flexibility without long term commitments.
Best For:
Azure HDInsight is best suited for businesses already invested in the Microsoft Azure ecosystem, such as financial services, manufacturing and retail companies.
Comparative Summary of Big Data Platforms
| Platform | Best For | Key Strengths | Pricing Model |
| Apache Hadoop | Large-scale storage | Cost-effective, highly scalable | Open-source |
| Apache Spark | Real-time data processing | High speed, supports ML | Open-source |
| Cloudera | Enterprise-grade analytics | Security, hybrid cloud support | Subscription-based |
| Amazon EMR | AWS-based analytics | Scalability, integration with AWS | Pay-as-you-go |
| Azure HDInsight | Microsoft Azure users | Integration with Azure, security | Pay-as-you-go |
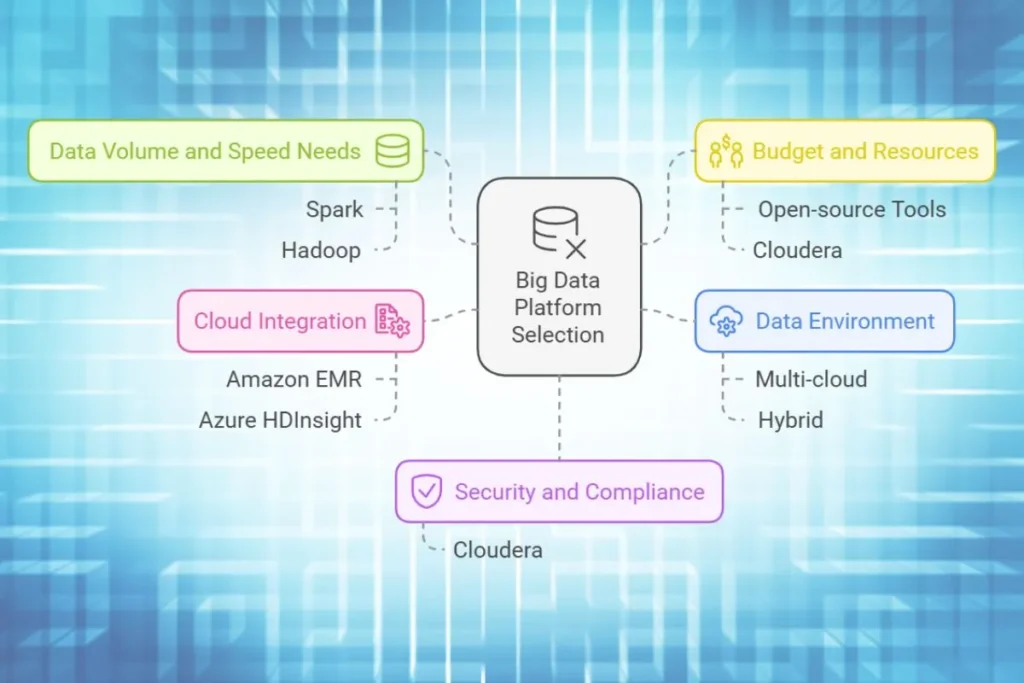
How to Choose the Right Big Data Platform for Your Business
When deciding on a big data platform, consider the following factors:
1. Data Volume and Speed Needs:
If your business processes data in real time, Spark is an ideal choice due to its in memory capabilities. For large scale, batch processing, Hadoop might be more suitable.
2. Security and Compliance:
For businesses that need comprehensive data governance, Cloudera provides enterprise level security and compliance features, which makes it suitable for regulated industries.
3. Budget and Resources:
Open source tools like Hadoop and Spark offer cost effective solutions but may require in house expertise. Cloudera’s platform, while more expensive, provides additional support and integration options.
4. Data Environment:
For businesses operating in multi cloud or hybrid environments, Cloudera’s CDP offers flexible deployment options.
5. Cloud Integration:
For companies using AWS or Azure, Amazon EMR and Azure HDInsight provide seamless integration with existing services, simplifying deployment and management.
Real World Case Studies: Big Data in Action
Case Study 1: Walmart’s Use of Hadoop for Inventory Management
Walmart uses Hadoop to analyze large amounts of customer transaction data, which optimizes inventory levels across its global locations. Hadoop enables Walmart to quickly process historical sales data, predict demand and ensure popular products are always available, which improves customer satisfaction.
Case Study 2: Real Time Processing with Apache Spark at Netflix
Netflix uses Spark to power its recommendation system, which analyzes user data to deliver personalized content suggestions. Spark’s in memory processing capabilities allow Netflix to analyze viewing behavior in real time, which enhances user engagement and retention.
Case Study 3: Cloudera’s Compliance Capabilities at HSBC
HSBC, a global financial services organization, uses Cloudera’s data platform to meet strict data security regulations. Cloudera’s governance and compliance features allow HSBC to manage sensitive data effectively, which ensures it meets financial industry standards while harnessing data for analytics.
Conclusion:
The demand for big data analytics platforms will continue to grow as more businesses rely on data driven decision making. Platforms like Hadoop, Spark, Cloudera, Amazon EMR and Azure HDInsight each have unique strengths that cater to different business needs and data challenges.
Choosing the right platform depends on your data goals, budget and existing technology stack. With the right big data platform, businesses can derive actionable tips, innovate faster and maintain a competitive edge over their competitor.
By understanding the strengths and limitations of each platform, you can make a more informed choice to utilize the full potential of big data for your business.
Disclaimer: The websites mentioned above might evolve over time. Always refer to the website and their official documentation for the most accurate and updated information as well as latest offerings, plans and prices etc.
I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.